

type
Page
status
Invisible
date
Nov 6, 2025
slug
paper/connected-vehicle-paper-review/01
summary
第1篇精读论文
tags
车联网
机器学习
category
icon
password
复现
打开anconda promt,执行下面命令
安装对应库,执行即可。其中的FCBF库无法使用pip安装,直接git相关文件到执行目录下即可
然后执行jupyter文件即可得到结果
代码分析
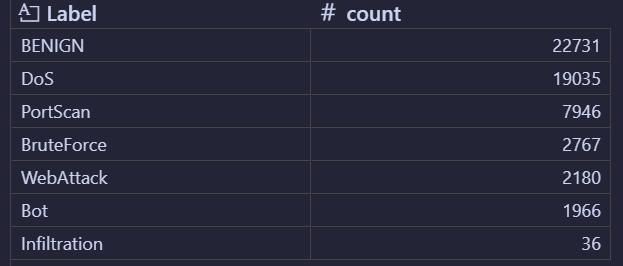
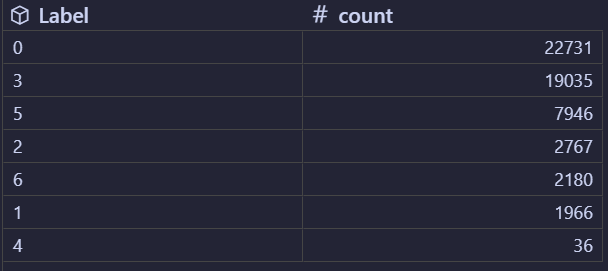
代码分析部分用的数据集是
CICIDS2017_sample.csvPreprocessing (normalization and padding values)
预处理(归一化和值填充)
首先筛选出df中数据类型的非字符串的列索引,然后对每一列进行标准归一化,然后把空值全部置0
Data sampling
数据采样
LabelEncoder 是 scikit-learn(Python 机器学习库)中的工具,专门用于将分类变量(如字符串、枚举值等非数值类型的标签)转换为整数编码(如 0、1、2...)。执行后变化如下图,原先用字符串表示的类别转换为文字编码
然后分离得到少数类和多数类样本
从多数类数据(df_major)中分离出 “特征数据(X)” 和 “标签数据(y)”
使用 MiniBatchKMeans 算法对多数类的特征数据(X)进行聚类,将相似的样本划分到不同的 “簇(cluster)” 中,为后续 “从每个簇中按比例抽取样本” 做准备,从而实现具有代表性的多数类下采样。
MiniBatchKMeans 是 KMeans 聚类算法的高效变种,适用于大规模数据集:它通过随机选取 “小批量样本” 进行迭代训练(而非使用全部数据),在保证聚类效果接近 KMeans 的同时,大幅减少计算时间和内存消耗,非常适合处理网络流量这类大规模数据。将聚类得到的 “簇标签” 与原始多数类数据关联起来,为后续 “按簇采样” 提供依据
调整数据框
df_major中 “标签列(Label)” 的位置,将其移动到指定的列索引位置(第 78 位,从 0 开始计数)对多数类数据按 “簇” 进行 “等比例采样”,从每个簇中抽取固定比例的样本,最终得到具有代表性的多数类子集
df_major.groupby('klabel'):按klabel列(簇标签,0 到 999)对多数类数据框df_major进行分组,得到 1000 个小组(每个小组对应一个簇的所有样本)。
group_keys=False:设置分组后不保留klabel作为结果的索引(避免索引冗余,让输出更简洁)。
.apply(typicalSampling):对每个分组(每个簇)应用typicalSampling函数,即每个簇都按 0.8% 的比例随机采样。
- 最终
result是所有簇的采样结果合并后的新数据框,包含多数类中 “每个簇的代表性样本”。
完成多数类采样结果的 “清理” 与 “少数类样本的合并”,最终得到一个 “多数类采样后 + 少数类完整保留” 的平衡数据集,把处理后的结果保存到对应文件中
split train set and test set
划分训练集和测试集
Feature engineering
特征工程
Feature selection by information gain
通过信息增益进行特征选择
使用 mutual information计算每个特征对目标标签的重要性
从 scikit-learn 库的特征选择模块中导入
mutual_info_classif 函数。该函数是用于分类问题的互信息计算工具,专门衡量 “特征” 与 “离散目标标签(y)” 之间的依赖关系(即特征包含多少关于目标标签的 “信息量”),数值越高表示该特征对分类的贡献越大(类似信息增益的作用)对特征按 “互信息重要性分数” 进行排序,并累加所有特征的重要性分数,同时按排序顺序收集特征名
map(lambda x: round(x, 4), importances)importances是之前通过mutual_info_classif计算得到的特征重要性数组(每个元素对应一个特征的互信息值)。
lambda x: round(x, 4)是一个匿名函数,作用是将每个重要性分数四舍五入保留 4 位小数(简化数值,便于查看和后续处理)。
map(...)会对importances中的每个元素应用这个匿名函数,返回一个 “处理后的重要性分数” 的可迭代对象。
- 循环遍历排序后的
f_list,每次迭代将当前特征的重要性分数累加到Sum中(得到 “前 i+1 个特征的累积重要性”),同时将特征名按重要性顺序存入fs列表。
基于 “相对重要性占比” 筛选特征,只保留累积重要性达到 90% 的核心特征
Feature selection by Fast Correlation Based Filter (FCBF)
The module is imported from the GitHub repo: https://github.com/SantiagoEG/FCBF_module
通过 FCBFK 算法完成 “指定数量的特征筛选”,并通过
shape验证筛选结果是否符合预期(确保保留 20 个特征),为后续模型训练提供精简且有效的输入特征(减少冗余,提升效率)。
fit_transform(X_fs, y) 已经包含了 fit(X_fs, y) 的功能 —— 它会先执行 fit 完成模型训练(确定特征筛选规则),再执行 transform 完成特征筛选并返回结果。Re-split train & test sets after feature selection
特征选择之后重新划分训练集和测试集
SMOTE to solve class-imbalance
通过配置 SMOTE 过采样器,后续可调用其
fit_resample 方法,对特征数据(X)和标签(y)执行过采样,生成标签为 2 和 4 的合成样本,最终得到 “少数类样本量提升至 1000” 的平衡数据集
smote.fit_resample(X_train, y_train) 是 SMOTE 过采样器的核心方法,包含两个关键步骤:fit(拟合):让 SMOTE 模型学习训练集X_train中少数类样本(标签为2和4)的分布特征(如样本的近邻关系、特征空间中的分布模式),为生成合成样本做准备。
resample(重采样):根据fit阶段学习到的分布,为标签为2和4的少数类生成合成样本(而非简单复制原始样本),直到这两个类别的样本数量达到sampling_strategy中指定的1000(其他类别的样本数量保持不变)。
Machine learning model training
Training four base learners: decision tree, random forest, extra trees, XGBoost
Apply XGBoost
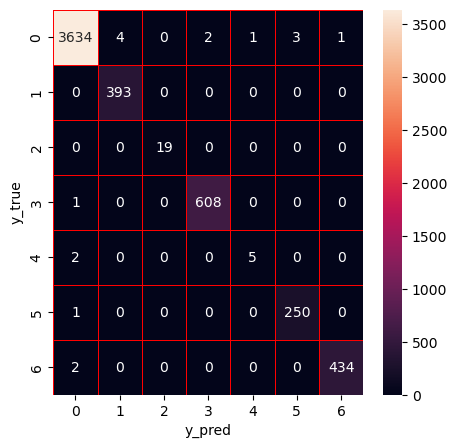
初始化一个包含 10 棵树的 XGBoost 分类器,用训练集数据训练模型后,在测试集上进行评估,通过计算准确率、加权精确率、召回率、F1 分数,打印详细的分类报告(含各类别具体指标),并生成混淆矩阵热力图进行可视化,以此全面分析模型的分类性能。
Hyperparameter optimization (HPO) of XGBoost using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
Based on the GitHub repo for HPO: https://github.com/LiYangHart/Hyperparameter-Optimization-of-Machine-Learning-Algorithms
核心功能是使用贝叶斯优化工具
hyperopt对 XGBoost 分类器的超参数进行自动搜索,找到能最大化测试集准确率的最优参数组合使用经过超参数优化后的 XGBoost 分类器进行模型训练,并分析其分类性能
使用训练好的 XGBoost 模型(
xg)分别对训练集和测试集的特征数据进行预测,生成对应的预测标签,为后面的集成学习做准备Apply RF
训练一个随机森林(Random Forest)分类器
Hyperparameter optimization (HPO) of random forest using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
Based on the GitHub repo for HPO: https://github.com/LiYangHart/Hyperparameter-Optimization-of-Machine-Learning-Algorithms
使用经过超参数优化后的随机森林(Random Forest)分类器进行模型训练
使用训练好的 XGBoost 模型(
rf_hpo)分别对训练集和测试集的特征数据进行预测,生成对应的预测标签**,为后面的集成学习做准备Apply DT
训练一个决策树(Decision Tree)分类器
Hyperparameter optimization (HPO) of decision tree using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
Based on the GitHub repo for HPO: https://github.com/LiYangHart/Hyperparameter-Optimization-of-Machine-Learning-Algorithms
使用优化过的决策树进行预测
保存预测结果
Apply ET
训练一个极端随机树(Extra Trees)分类器
Hyperparameter optimization (HPO) of extra trees using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
Based on the GitHub repo for HPO: https://github.com/LiYangHart/Hyperparameter-Optimization-of-Machine-Learning-Algorithms
使用优化后的ET树进行训练
保存预测值
Apply Stacking
The ensemble model that combines the four ML models (DT, RF, ET, XGBoost)
构建基础模型训练集预测结果的 DataFrame
将各模型的预测结果从 “一维数组”(形状为
(n_samples,))重塑为 “二维数组”(形状为(n_samples, 1))。后续需要将这些预测结果作为 “新特征” 拼接成特征矩阵,而特征矩阵的格式要求是二维(样本数 × 特征数),每个模型的预测结果将作为一个单独的特征列;使用
np.concatenate在列方向(axis=1) 拼接各模型的预测结果数组,形成新的特征矩阵。
最终形成新的训练集和测试集实现 Stacking(堆叠)集成学习策略:以 XGBoost 作为 “元模型”(次级模型),基于多个基础模型的预测结果(元特征)进行训练,并全面评估该集成模型在测试集上的分类性能|
Hyperparameter optimization (HPO) of the stacking ensemble model (XGBoost) using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
Based on the GitHub repo for HPO: https://github.com/LiYangHart/Hyperparameter-Optimization-of-Machine-Learning-Algorithms
使用最优的参数
Anomaly-based IDS
Generate the port-scan datasets for unknown attack detection
生成用于未知攻击检测的端口扫描数据集
对 CICIDS2017 网络流量数据集进行筛选和标签转换,分离出 “端口扫描攻击” 和 “非端口扫描数据”,并分别保存为两个二分类数据集
对
df1的标签进行二值化:将所有Label>0(即除正常流量外的其他攻击)统一标记为1(代表 “异常”),保留Label=0(代表 “正常”)
对df2的标签进行二值化:将Label=5统一标记为1(代表 “异常”),形成 “端口扫描攻击” 的单一异常数据集标签5是原标签portscan映射而来
Read the generated datasets for unknown attack detection
读取数据
归一化,填充空值为0
从
df1中筛选出所有正常流量样本(Label=0),存储到df2p中
为端口扫描攻击数据集(df2)补充适量的正常网络流量样本,构建一个包含 “正常流量” 和 “端口扫描攻击” 的平衡二分类数据集合并df1,df2为df,提取特征数据X和标签数据y
Feature engineering (IG, FCBF, and KPCA)
Feature selection by information gain (IG)
Feature selection by Fast Correlation Based Filter (FCBF)
The module is imported from the GitHub repo: https://github.com/SantiagoEG/FCBF_module
使用基于相关性的快速特征选择方法(FCBF 系列中的 FCBFK),对已初步降维的特征矩阵(X_fs)进行进一步筛选,保留指定数量(20个)的关键特征
kernel principal component analysis (KPCA)
- 核主成分分析是 “主成分分析(PCA)” 的扩展,通过 “核技巧(Kernel Trick)” 处理非线性可分数据:先将低维特征映射到高维空间(使其在高维线性可分),再在高维空间进行线性降维,最终得到低维的非线性特征表示。
- 关键参数解析:
n_components = 10:指定降维后保留的特征数量为 10(即最终输出的特征矩阵X_kpca形状为(样本数, 10))。kernel = 'rbf':选择 “径向基函数(RBF)” 作为核函数(最常用的非线性核函数之一),适合捕捉特征间的复杂非线性关系(如网络流量数据中可能存在的非线性关联)。
Train-test split after feature selection
Solve class-imbalance by SMOTE
执行过采样,将标签为
1的少数类样本数量调整为18225个Apply the cluster labeling (CL) k-means method
定义一个基于无监督聚类算法(MiniBatchKMeans)的分类任务评估函数,通过将聚类得到的 “簇标签” 映射到原始分类标签(0 和 1),实现对聚类算法在分类场景下的性能评估
定义聚类分类评估函数
CL_kmeans
函数参数说明:X_train/X_test:训练集 / 测试集特征(降维后的特征矩阵);
y_train/y_test:训练集 / 测试集的真实标签(0 和 1,如 0 = 正常,1 = 异常);
n:聚类的簇数量(n_clusters);
b:MiniBatchKMeans 的批处理大小(batch_size,默认 100,控制每次训练的样本量,影响效率)。
- 先用训练集数据进行聚类,得到每个样本的 “簇标签”(无监督,不依赖原始分类标签);
- 结合训练集的真实分类标签(0/1),统计每个簇中 “正常样本(0)” 和 “异常样本(1)” 的数量,将簇标记为 “正常簇”(正常样本多)或 “异常簇”(异常样本多);
- 用同样的聚类模型对测试集聚类,再根据簇的标记规则,将测试集的簇标签转换为分类预测结果(0/1),最后通过分类指标评估性能。
- 使用 MiniBatchKMeans 进行聚类
- )建立 “簇标签” 与 “原始分类标签” 的映射关系:聚类是无监督学习,得到的簇标签(0~n-1)本身没有实际意义,需要通过训练集的真实标签(
y_train)将簇映射到原始类别(0 或 1)。通过训练集的真实标签,判断每个簇的 “主要类别”—— 如果簇中正常样本(0)更多,就将该簇映射为 0;如果异常样本(1)更多,就映射为 1。
- 将测试集簇标签转换为分类预测结果
- 评估聚类分类性能
Hyperparameter optimization of CL-k-means
Tune "k"
使用贝叶斯优化(Bayesian Optimization, BO)结合高斯过程(Gaussian Process, GP)对 “聚类标记(CL)k-means 方法” 中的关键超参数(簇数量
n_clusters)进行优化按论文中这里应该不用执行,采用BO-GP而不是BO-TPE
Apply the CL-k-means model with biased classifiers
这段代码定义了一个名为
Anomaly_IDS的函数,核心功能是结合 “CL-kmeans 聚类标记” 进行基础异常检测,并构建 “有偏分类器(Biased Classifier)” 优化易错样本的预测效果(针对 CL-kmeans 误判的样本做专项优化),最终在新数据集上验证检测性能。- CL-kmeans 基础异常检测(复用前文逻辑)
- 有偏分类器构建:“有偏分类器” 指针对 CL-kmeans 的 “假正例(FPL)” 和 “假负例(FNL)” 样本专项优化的分类器—— 通过扩充易错样本的训练数据,提升对这类样本的预测准确性,弥补 CL-kmeans 的不足。
- 新数据集(df2)上验证 CL-kmeans 性能
整个
Anomaly_IDS函数是一个 **“基础检测 + 易错优化” 的两阶段异常检测框架 **:- 基础阶段:用 CL-kmeans 实现无监督异常检测,快速得到初步结果;
- 优化阶段:识别 CL-kmeans 的假正 / 假负样本,构建有偏分类器针对性优化(解决基础检测的漏检 / 误检问题);
- 验证阶段:在新数据集上验证基础检测的泛化能力,为后续融合有偏分类器的结果做准备。
通过 “聚类 + 有偏分类器” 的组合,平衡无监督检测的高效性和有监督优化的准确性,尤其适合网络异常检测(如端口扫描检测)中 “标签稀缺但需降低误判” 的场景。
运行结果
The Signature-based IDS
Apply XGBoost

Hyperparameter optimization (HPO) of XGBoost using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
Apply RF
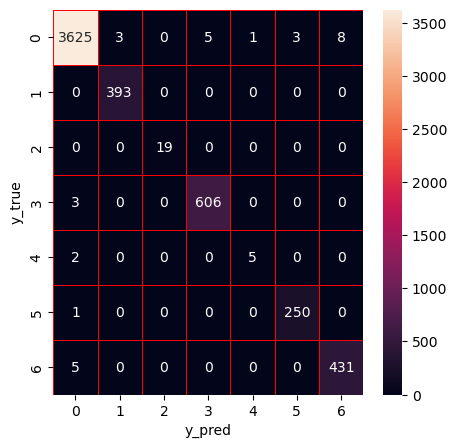
Hyperparameter optimization (HPO) of random forest using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
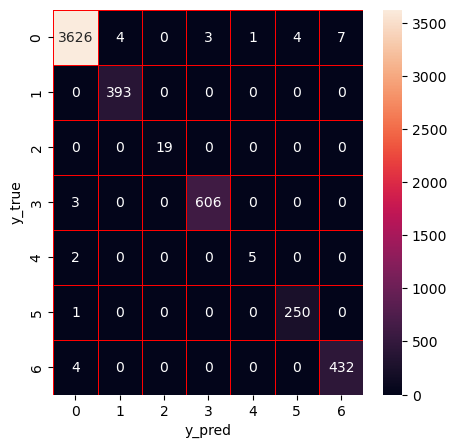
Apply DT
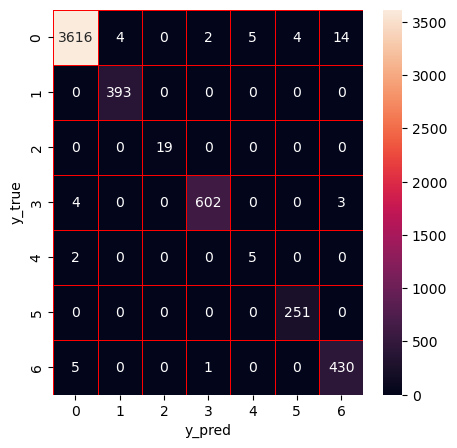
Hyperparameter optimization (HPO) of decision tree using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
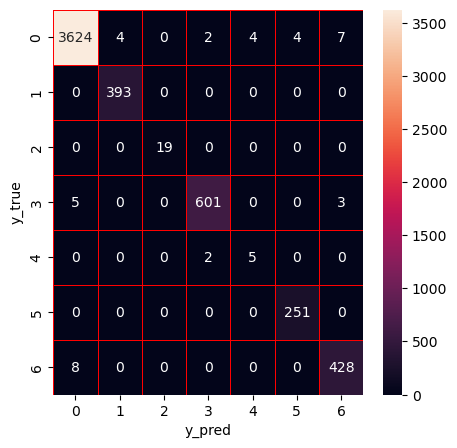
Apply ET
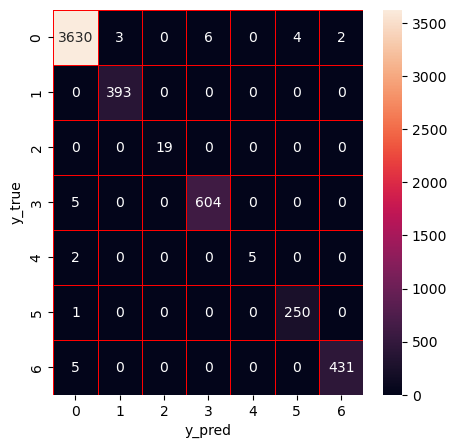
Hyperparameter optimization (HPO) of extra trees using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
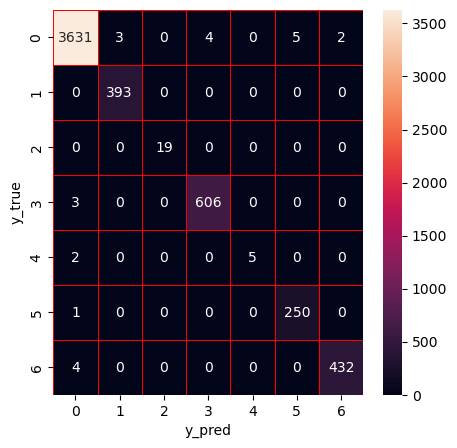
Apply Stacking
The ensemble model that combines the four ML models (DT, RF, ET, XGBoost)
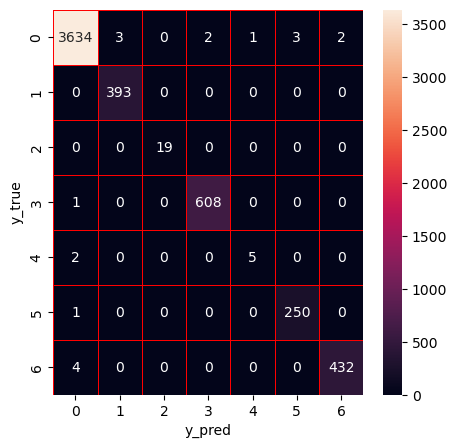
Hyperparameter optimization (HPO) of the stacking ensemble model (XGBoost) using Bayesian optimization with tree-based Parzen estimator (BO-TPE)
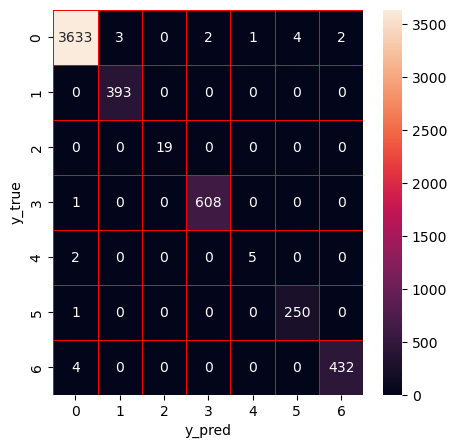
Anomaly-based IDS
这一部分源代码没有给出random_state参数的值,无法固定导致无法复现作者给出的结果
Apply the cluster labeling (CL) k-means method
Hyperparameter optimization of CL-k-means
研究背景
尽管许多前人的工作已经在开发入侵检测系统方面取得了一些成功,但由于网络流量的数据量大,可用的网络特征众多,网络攻击模式多种多样,车联网入侵检测仍然是一个具有挑战性的问题。
下图是该论文所提出的系统与一些已知论文中所提出系统的区别
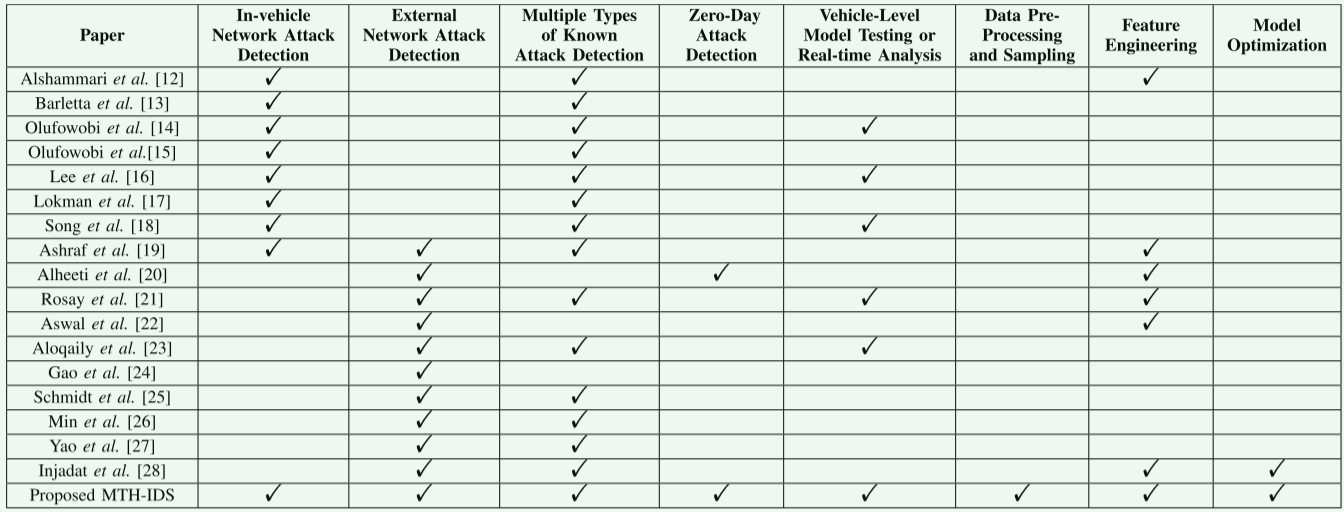
MDH-IDS:
- 支持车内网络攻击检测(In-vehicle Network Attack Detection)
- 支持外部网络攻击检测(External Network Attack Detection)
- 支持多种已知攻击类型检测(Multiple Types of Known Attack Detection)
- 支持零日攻击检测(Zero-Day Attack Detection)
- 具备数据预处理与采样(Data Pre-Processing and Sampling)能力
- 重视特征工程(Feature Engineering)
- 支持模型优化(Model Optimization)
- 支持车辆级模型测试或实时分析(Vehicle-Level Model Testing or Real-time Analysis)
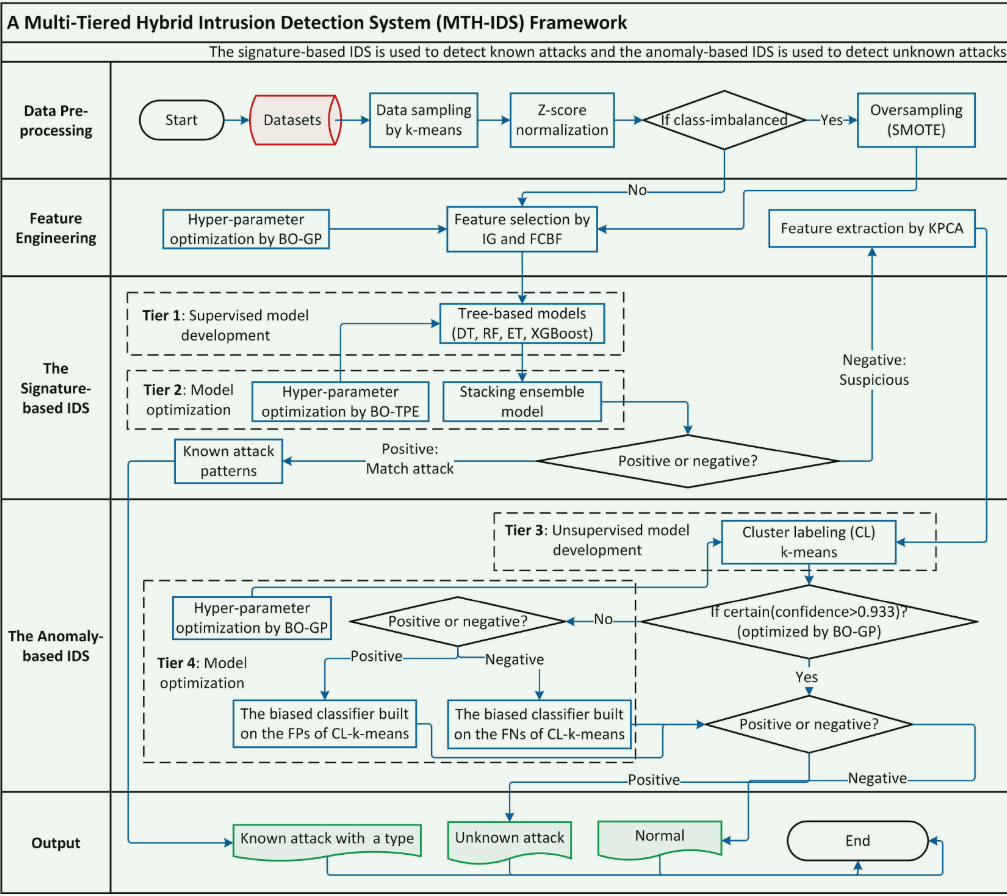
系统框架
1. 数据预处理(Data Pre-processing)
- 从数据集(Datasets)开始,先通过k-means 进行数据采样,再进行Z-score 归一化。
- 检查数据是否类别不平衡:
- 若是,执行SMOTE 过采样;
- 若否,直接进入 “特征工程” 阶段。
2. 特征工程(Feature Engineering)
- 先通过贝叶斯优化(BO-GP)进行超参数优化,再结合信息增益(IG)和 FCBF 算法进行特征选择,最后通过核主成分分析(KPCA)进行特征提取。
3. 基于特征的 IDS(Signature-based IDS,用于检测已知攻击)
- Tier 1:开发基于树的有监督模型(决策树 DT、随机森林 RF、极端树 ET、XGBoost)。
- Tier 2:通过贝叶斯优化(BO-TPE)进行超参数优化,构建堆叠集成模型(Stacking ensemble model)。
- 对模型输出进行判断:
- 若结果为Positive(匹配攻击),则识别为已知攻击模式(Known attack patterns);
- 若为Negative(不匹配),则进入 “基于异常的 IDS” 阶段。
4. 基于异常的 IDS(Anomaly-based IDS,用于检测未知攻击)
- Tier 3:开发无监督聚类模型,采用聚类标记(CL)k-means算法。
- 检查聚类结果的置信度(是否 > 0.933,该阈值由 BO-GP 优化):
- 若 “确定”,直接判断结果正负;
- 若 “不确定”,进入Tier 4:通过 BO-GP 进行超参数优化,针对 CL-k-means 的假正例(FPs)和假负例(FNs) 构建有偏分类器,再判断结果正负。
5. 输出(Output)
- 根据上述流程的最终判断,输出三类结果:
- Known attack with a type(已知攻击及类型);
- Unknown attack(未知攻击,即零日攻击);
- Normal(正常流量),流程结束。
所用技术
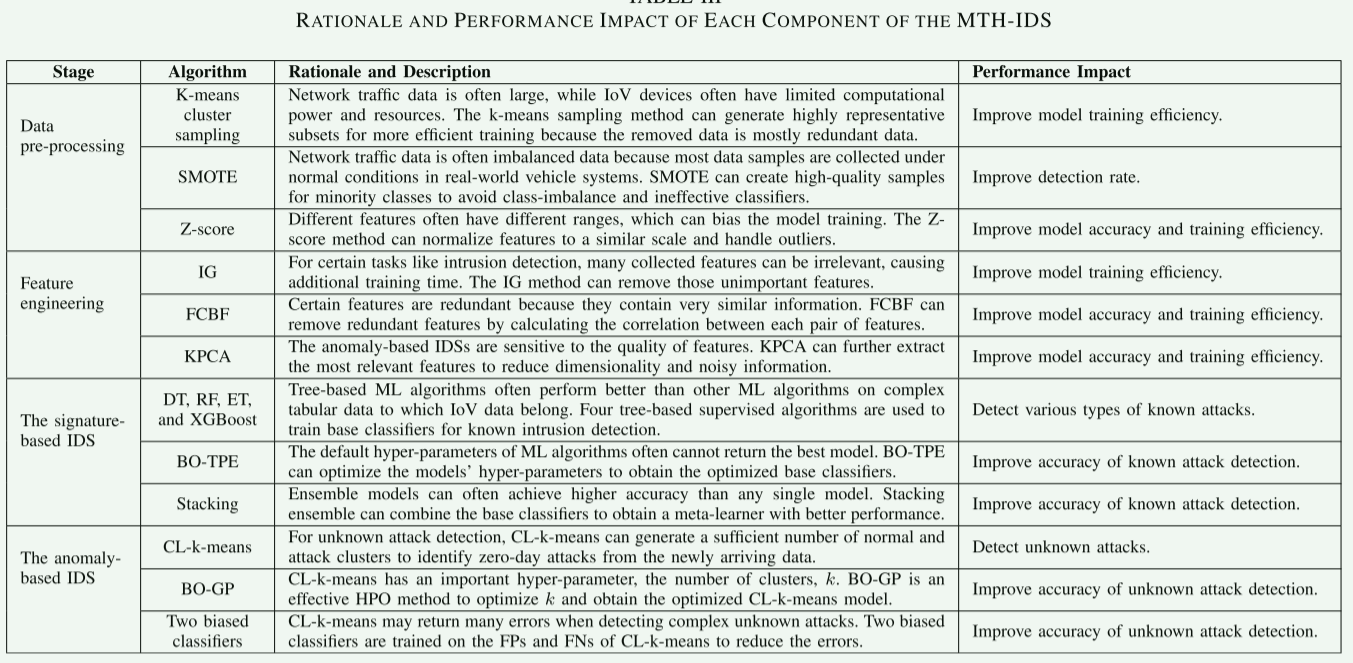
一、数据预处理(Data pre-processing)
- K-means cluster sampling:K-means 是一种无监督聚类算法,通过迭代将数据划分为多个簇(簇内样本相似度高,簇间相似度低)。在车联网场景中,利用 K-means 对网络流量数据采样时,会优先保留每个簇的代表性样本,过滤冗余数据(如多个高度相似的正常流量样本)。这样既减少了训练数据量,又保证了数据的代表性,显著提升模型训练效率,同时适配车联网设备有限的计算资源。
- SMOTE:全称为 “Synthetic Minority Oversampling Technique”,是专门解决类别不平衡的过采样算法。它通过在少数类样本(如攻击样本)的邻近样本之间 “插值” 生成新样本(而非简单复制)。例如,若某攻击样本的邻近样本有 A 和 B,SMOTE 会在 A 和 B 的特征空间中生成新的攻击样本,使其既保留攻击特征的合理性,又避免过拟合。这种方法为少数类补充了高质量样本,有效提升攻击检测率,解决 “正常样本多、攻击样本少” 导致的模型偏向性问题。
- Z-score:公式为(其中是均值,是标准差)。它将不同范围的特征归一化到以 0 为中心、标准差为 1 的尺度,消除特征量纲差异对模型的干扰(如 “流量大小” 单位是 GB,“包数量” 单位是个,量纲不同但重要性相当)。同时,Z-score 对异常值(如远高于均值的流量峰值)的鲁棒性较强,能让模型更稳定地学习特征模式,兼顾准确率和训练效率。
二、特征工程(Feature engineering)
- IG(信息增益):基于 “熵” 的概念量化特征对标签的 “贡献度”。熵衡量数据的混乱程度,信息增益是 “特征划分前的熵 - 划分后的熵”,值越大说明该特征对标签的区分能力越强。在入侵检测中,IG 会筛选出那些能大幅降低 “正常 / 攻击” 标签混乱度的特征,移除无关特征(如与攻击检测完全无关的设备 ID),减少训练时间,让模型更聚焦于关键特征。
- FCBF(Fast Correlation-Based Filter):核心逻辑是 “保留与标签高度相关、且与其他特征冗余度低的特征”。它先计算每个特征与标签的相关性(如互信息),再计算特征对之间的冗余度(如相关性系数)。若特征 A 与特征 B 高度冗余,且 A 与标签的相关性低于 B,则移除 A。这样既保证了特征的 “相关性”(对检测有帮助),又避免了 “冗余性”(多个特征携带重复信息),让模型用更少、更精炼的特征达到更高准确率。
- KPCA(Kernel PCA):是主成分分析(PCA)的扩展,引入 “核技巧” 将低维非线性数据映射到高维线性可分空间,再在高维空间中进行 PCA 降维。例如,原始流量特征可能存在 “流量大小与攻击类型” 的非线性关系,KPCA 通过 RBF 核(径向基函数)将其映射到高维后,能线性区分正常和攻击模式。这种方法既提取了最相关的特征,又降低了维度,特别适配异常检测对特征质量的高要求,提升模型对未知攻击的识别能力。
三、基于签名的 IDS(The signature-based IDS,检测已知攻击
- DT、RF、ET、XGBoost:
- DT(决策树):单棵树模型,通过对特征 “if-else” 式的划分来识别攻击模式,结构简单但易过拟合。
- RF(随机森林):多棵决策树的集成,每棵树随机选择特征和样本训练,通过投票输出结果,鲁棒性强、不易过拟合。
- ET(极端树):RF 的改进版,分割特征时完全随机选择(而非找最优分割点),训练更快,适合大规模数据。
- XGBoost:梯度提升树的优化版,通过 “加法模型” 迭代生成树(每棵树修正前序模型的误差),带正则化项防止过拟合,支持并行计算,在分类任务中精度极高。 这四类树模型在车联网的表格型数据(如流量大小、包类型、时延等特征构成的数据集)上表现出色,能精准识别 “已知攻击” 的特征模式(如 DDoS 攻击的流量峰值模式)。
- BO-TPE(Bayesian Optimization with Tree-structured Parzen Estimator):是贝叶斯优化的高效变体,通过分别建模 “高性能参数” 和 “低性能参数” 的概率分布,每次迭代优先选择 “更可能属于高性能” 的超参数(如树的深度、学习率等)进行评估。相比网格搜索或随机搜索,TPE 能以更少的迭代次数找到最优超参数,大幅提升已知攻击检测的准确率。
- Stacking(堆叠集成):属于 “分层集成学习”,第一层是多个基分类器(如 DT、RF、XGBoost),它们各自输出预测结果;第二层是 “元分类器”(如逻辑回归),学习如何组合这些基分类器的输出,从而得到更优的最终预测。这种方式结合了不同模型的优势,比单一模型的准确率更高,能更可靠地识别已知攻击。
四、基于异常的 IDS(The anomaly-based IDS,检测未知攻击)
- CL-k-means(Cluster Labeling k-means):先对数据无监督聚类(将相似样本划分为簇),再利用训练集的标签信息,将簇 “标记” 为 “正常簇”(簇中正常样本多)或 “攻击簇”(簇中攻击样本多)。测试时,若样本属于 “攻击簇” 则判定为未知攻击,属于 “正常簇” 则判定为正常。这种方法不依赖 “已知攻击的签名”,而是通过数据的 “异常分布” 识别未知攻击,专门用于零日攻击(未知攻击)的检测。
- BO-GP(Bayesian Optimization with Gaussian Process):基于高斯过程(一种概率模型)对 “超参数(如 CL-k-means 的簇数量k)与检测性能” 的关系进行建模,每次迭代选择 “最可能提升性能” 的k进行评估,逐步逼近最优值。相比手动调参,BO-GP 能高效找到使未知攻击检测准确率最高的k,显著提升异常检测的精度。
- Two biased classifiers(两个有偏分类器):针对 CL-k-means 的 “假正例(FPs,将正常样本误判为攻击)” 和 “假负例(FNs,将攻击样本误判为正常)” 训练。例如,对假正例样本(正常但被误判的样本),训练一个分类器专门学习 “正常样本的细微特征”;对假负例样本(攻击但被误判的样本),训练另一个分类器专门学习 “攻击样本的隐蔽特征”。这两个分类器能修正 CL-k-means 的误判,进一步提升未知攻击检测的准确率。
验证指标
数据集
用于外部网络
用于车内网络
采用准确率(Acc)、检测率(DR)、误报率(FAR)和 F1 分数等多项指标,对所提入侵检测系统(IDS)的性能进行全面评估 。通过计算所提模型的真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN),所用指标可通过以下公式计算。

模型执行时间通过十次交叉验证或坚持验证中模型训练和验证时间的平均值来计算,用于评估模型的效率。
一个高效的入侵检测系统应该能够同时实现高F1分数和低执行时间。
不足之处
对于已知攻击的检测比较完善
对于未知攻击的检测
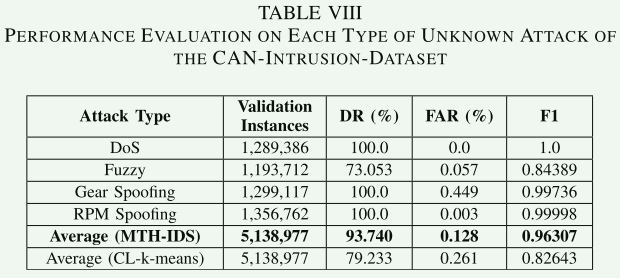
未知 CAN 攻击检测的评估结果如表 VIII 所示。对于 DoS、挡位欺骗和 RPM 欺骗攻击类型,所提系统可实现 100% 的检测率(DR)、极低的误报率(FAR,0.0%–0.449%)以及极高的 F1 分数(超过 0.997)。然而,模糊攻击的检测率(DR)和 F1 分数要低得多,分别为 73.053% 和 0.84389。
这是因为模糊攻击数据包的特征值是随机数值,且某些随机值可能与正常数据包非常相似,这使得无监督学习算法难以对它们进行区分。
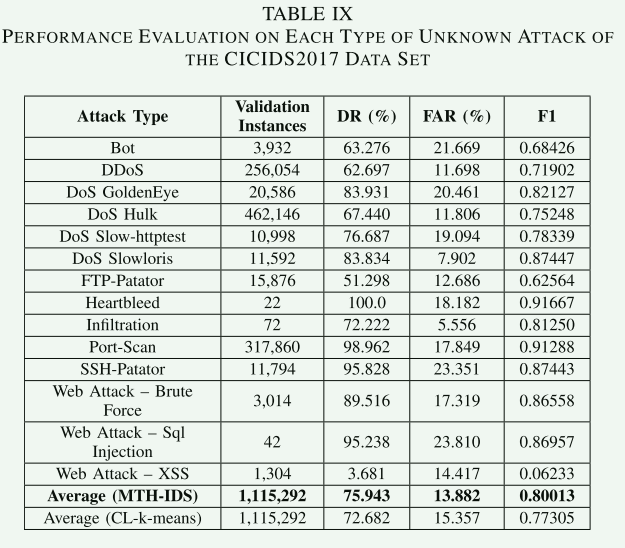
从表9可以看出,所提出的系统在应用于不同类型的未知攻击的实验中表现出不同的性能。通过实施所提出的方法,大多数攻击类型的FAR都处于低于20%的低水平。“心脏出血”、“端口扫描”、“SSH-Patator”、“Web攻击-暴力”和“Web攻击-SQL注入”攻击的DR较高(从89.516%到100%),而其他类型的攻击的DR相对较低(从51.298%到83.931%)。大多数攻击类型的F1-得分都大于0.80。
该系统唯一不能有效检测的攻击类型是网络攻击-XSS,其结果显示非常低的F1得分(0.062),因为它们的数据分布非常类似于正态数据分布。该模型在所有攻击上的平均F1得分为0.80013,高于没有偏向分类器的CL-k-Means模型(0.77305)。
总结:提出的入侵检测系统可以检测到大多数以前未见的攻击类型,在车内和外部车载网络上都具有相对较高的DR和相对较低的FAR。然而,由于有效检测零日攻击仍然是一个悬而未决的研究问题,因此仍有一些改进的空间。