

type
Page
status
Invisible
date
Nov 30, 2025
slug
summary
第3篇精读论文
tags
车联网
机器学习
category
icon
password
Deep Multimodal Learning for Real-Time DDoS Attacks Detection in Internet of Vehicles 原文链接:https://ieeexplore.ieee.org/document/11160909
文章总结
一、论文基本信息
- 会议与发表:2025 年 IEEE 国际通信会议(ICC)下一代网络与互联网专题研讨会论文
- 作者团队:来自阿尔及利亚、法国多所高校及实验室的 Mohamed Ababsa 等人
- 核心主题:提出基于深度多模态学习(DML)的车联网(IoV)实时分布式拒绝服务(DDoS)攻击检测方法,强化智能交通系统网络安全
二、研究背景与问题提出
- 行业现状
- 世界卫生组织报告显示,全球每年约 119 万人死于道路交通事故,智能交通系统(ITS)和车联网(IoV)成为提升道路安全与通行效率的关键技术。
- 车联网的开放式连接使其面临严重网络安全威胁,其中 DDoS 攻击危害极大,可能导致交通混乱、通信中断甚至交通事故。
- 现有研究局限
- 传统检测方法在攻击者密度动态变化时性能大幅下降,难以适配实时检测需求。
- 现有数据集存在类别不平衡问题,且仅覆盖少数 DDoS 攻击类型,限制模型泛化能力。
- 单一机器学习或深度学习模型存在短板,如 LSTM 响应时间长、GRU 检测精度不足等。
三、核心贡献
- 提出一种新型深度多模态学习模型,融合 LSTM、GRU(结合注意力与门控机制)和 MLP 分支,专门适配车联网 DDoS 实时检测场景。
- 在 F2MD 实时仿真平台部署该架构,通过自定义数据集验证,性能优于传统机器学习方法和现有主流技术,并提供开源实现。
- 解决了 VeReMi 数据集的局限性,生成类别均衡的数据集,涵盖 5 种 DDoS 攻击类型,适配不同攻击者密度场景。
四、系统模型与核心方法
(一)车联网与攻击模型
- IoV 网络架构:采用边缘 - 云混合架构,车辆通过 V2V(车对车)和 V2I(车对基础设施)通信,路侧单元(RSU)边缘服务器本地处理基础安全消息(BSMs),云端服务器负责模型训练与更新。
- 攻击类型:聚焦 5 种基于 VeReMi 扩展数据集的 DDoS 攻击,包括 DoS(超标准频率发包)、DoS Random(随机字段消息)、DoS Disruptive(重放邻居数据)、DoS Random Sybil(随机伪身份签名)、DoS Disruptive Sybil(冒用邻居身份签名)。
- 仿真平台:基于 F2MD 框架(VEINS 扩展),采用卢森堡迷你场景(LuSTMini)生成贴近真实场景的训练与验证数据集。
(二)数据集预处理
- 数据内容:包含 BSMs 时序数据(车速、加速度、位置等 14 个特征)和合理性检查数据(36 个特征)。
- 预处理操作:通过 BSM 转换器解析 JSON 格式数据,采用窗口大小为 20、步长为 1 的滑动窗口构建时序序列;平衡数据集类别分布,使各类别占比约 13%-17%;划分训练集与验证集,避免模型过拟合。
(三)DML 模型架构
模型包含两个核心分支,通过多模态中间融合整合特征,具体结构如下:
- LSTM - GRU 注意力分支:处理 BSMs 时序数据
- 输入层接收 20 步长、14 特征的时序序列。
- 经深度自适应输入归一化(DAIN)层处理非平稳数据,提升模型鲁棒性。
- 双向 LSTM 捕捉双向时序依赖,结合自注意力机制计算序列重要性得分,生成上下文向量。
- 门控机制融合原始 LSTM 输出与上下文向量,通过批归一化稳定训练,后续经全连接层与 GRU 层优化性能。
- MLP 分支:处理合理性检查的 36 个额外特征,经全连接层与批归一化处理,提取静态特征。
- 多模态融合:拼接两个分支输出,通过全连接层、ReLU 激活函数和批归一化处理,最终经 Softmax 输出层得到 6 类(5 种攻击 + 正常状态)的分类概率。
五、实验设置与结果
(一)实验配置
- 环境参数:基于 OMNET++ v5.6.2 和 SUMO 1.2.0 仿真,采用 NVIDIA Tesla P40 显卡训练;通信协议为 ITS - G5(IEEE 802.11p)。
- 训练参数:优化器为 Adam,学习率 0.001,损失函数为类别交叉熵,初始训练轮次 20 轮,自训练迭代 5 次,置信阈值 0.9,早停策略监测验证损失,耐心值 3 轮。
- 评估指标:采用召回率、精确率、F1 分数和准确率,对比传统模型(AdaBoost、决策树、KNN 等)在 10%、30%、50% 三种攻击者密度下的性能。
(二)核心实验结果
- 性能优势:DML 模型在所有密度场景下均表现最优,平均准确率达 96.63%。10% 密度时准确率 97.13%、精确率 99.92%;50% 高密度场景下仍保持 96.30% 的准确率,远超传统模型(如 AdaBoost 仅 79.21%)。
- 计算效率:DML 模型平均预测时间为 449.57ms,虽高于传统机器学习模型,但完全满足车联网实时检测需求,精度提升的收益远超计算成本增加。
- 对比相关工作:相较于现有主流方法,该模型的精确率(99.92%)和 F1 分数(98.51%)达到最优,且在高攻击者密度场景下的稳定性优势显著。
六、结论与未来方向
- 结论:提出的深度多模态学习模型通过融合 LSTM、GRU 与 MLP,结合注意力和门控机制,有效解决了车联网 DDoS 攻击实时检测的核心难题,在检测精度和环境适应性上优于现有方法。
- 未来计划
- 优化模型计算效率,适配资源受限的边缘设备。
- 在混合边缘 - 云系统、大规模城市网络等多元场景中测试部署,适配 5G - V2X 协议。
- 增强 F2MD 框架功能,支持新型 DDoS 攻击检测,助力车联网安全研究。
代码复现

DML
mohababsa • Updated Dec 5, 2025
作者给的相关链接里只有
train.csv和val.csv,是原始数据经过DataPreprocessing.ipynb 中的代码处理之后得到的,原始数据没有给出。此外,该作者的代码是用cpu版本的tensorflow版本运行的,直接使用gpu版本运行会卡死,需要修改才能正确运行环境准备
使用conda创建新环境
数据集


一个
train.csv和一个val.csv ,比例是8:2,train.csv有800000条数据数据集由两大类特征组成:
- BSM
- Plausibility Checks 合理性校验特征(MLP 分支,36 维)
- 标签
BSM
字段名 | 中文 | 解释说明 |
CreationTime | 消息生成时间 | 车辆生成 BSM 的仿真时间戳 |
ArrivalTime | 消息到达时间 | BSM 被 RSU / 接收节点接收的时间 |
RealId | 车辆真实 ID | 仿真中的车辆唯一真实身份 |
Pseudonym | 发送方伪身份 | 用于隐私保护(也是 Sybil 攻击关键字段) |
receiverId | 接收方真实 ID | 接收该 BSM 的车辆或 RSU |
receiverPseudo | 接收方伪身份 | 接收节点的匿名身份 |
Accel_x | X 轴加速度 | 车辆纵向/横向加速度分量 |
Accel_y | Y 轴加速度 | 同上 |
Heading_x | 航向向量 X 分量 | 车辆行驶方向 |
Heading_y | 航向向量 Y 分量 | 同上 |
Pos_x | X 坐标位置 | 车辆空间位置 |
Pos_y | Y 坐标位置 | 同上 |
Speed_x | X 轴速度 | 车辆速度分量 |
Speed_y | Y 轴速度 | 同上 |
Plausibility Checks 合理性校验特征
字段名 | 中文解释 | 解释说明 |
data_0 ~ data_35 | 合理性校验特征 | 车辆行为是否符合物理/交通规则 |
代码给了两个基线模型,用于与论文中提出的模型DML进行对比:
- LSTM-Dense-GRU with only BSMs sequences as input (without adding the plausibility checks data)——仅以 BSM 序列作为输入的 LSTM–Dense–GRU 架构(不包含可信性检查数据)
Deep Adaptive Input Normalization (DAIN) Layer
作用:对时间序列输入做“可学习的、自适应的归一化”
其包含以下三个步骤:
- Adaptive Average(自适应平移/去均值)
- Adaptive Scale(自适应缩放/标准化)
- Gating(门控调节强度)
BiLSTM(Bidirectional LSTM)
该网络属于循环神经网络(recurrent neural network,RNN)中的一种。RNN可以更好地处理序列信息。循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。
RNN(循环神经网络)


LSTM(长短期记忆网络)


BiLSTM(双向循环神经网络)

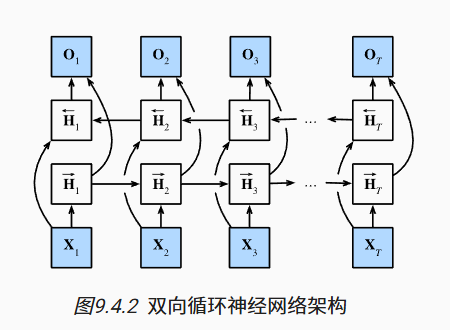
尽管双向 LSTM 在预测未来时间步的任务中可能引入不可得的未来信息,但在该论文所研究的离线序列分类场景中,模型在预测阶段可以访问完整的时间序列。因此,BiLSTM 作为序列编码器用于提取双向上下文特征是合理的,有助于提升对攻击行为整体模式的建模能力。
self-attention(自注意力)

GRU(门控循环单元)

MLP(多层感知机)


batch normalization(批量规范化)

代码运行结果

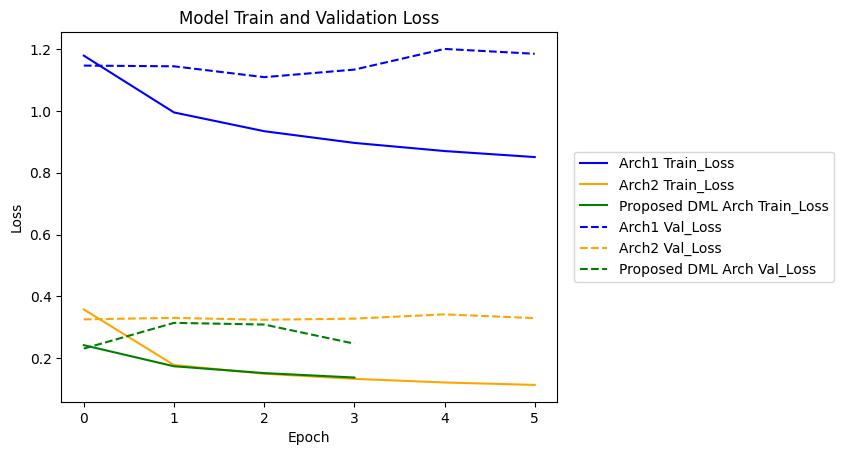
优化方案
问题1:
Pseudonym 是车辆在一段时间内使用的“临时身份标识”,用于在不暴露真实身份的情况下,维持通信连续性,是一个会周期性更换的匿名 ID。- 原方案首先是数据预处理部分有问题。原方案直接按大小为20的窗口进行滑窗,没有考虑不同车辆混合,这样会把不同车辆的数据放到一个时序窗口里。
- 改进:按 Pseudonym 分组滑窗。
make_windows_by_pseudonym()里先df.groupby("Pseudonym"),再组内CreationTime排序,然后只在组内滑窗。
问题2:
- 原方案使用验证集中的数据进行自训练,这相当于让模型看过考试答案再去考试,显然不合理。
- 改进:拆分原先的训练集,从中取一部分用于自训练,不参与前期的训练
伪标签筛选的双阈值机制(降低噪声引入)
伪标签样本需同时满足以下两个条件:
- 最大预测概率不低于阈值
- 最大预测概率与第二大概率的差值不小于margin阈值
这是因为仅基于最大概率筛选容易引入模型高度犹豫的边界样本(如两个类别概率接近),这类样本往往具有较高噪声风险。
通过引入 margin 约束,仅保留模型具有明确判别信心的样本,有效降低伪标签噪声,提高自训练的稳定性。
类别级伪标签数量上限(缓解类别不平衡)
在每一轮自训练中,对每个类别设置伪标签数量上限(per-class cap),并按置信度排序选取前若干个样本。
这是因为伪标签往往大量集中于多数类,若不加控制,自训练会进一步放大类别不平衡问题,导致少数攻击类的识别能力下降。
该策略在引入伪标签的同时维持了较为平衡的类别分布,有助于提升模型在少数攻击类上的表现。
增量式自训练与轻量微调(防止噪声放大)
自训练采用增量累加策略:每轮将新选出的伪标签样本加入已有 labeled 训练集,并仅进行1个epoch的微调,而非重新训练模型。
若在单轮中对大量伪标签进行多轮训练,伪标签噪声可能被过度放大,导致模型性能不稳定。
小步长、渐进式的参数更新方式使模型逐步吸收高置信样本信息,降低噪声伪标签对模型的负面影响,提高整体训练稳定性。
使用过的 unlabeled 样本即时移除(避免重复污染)
在每一轮自训练结束后,将已被选为伪标签的样本从 unlabeled pool 中移除,确保每个
unlabeled样本最多只被使用一次。重复使用同一批伪标签样本会导致训练集冗余,并可能放大噪声影响。
该机制保证了数据规模演化的清晰性,使自训练过程更加可控且统计意义明确。